Our Obligation: Open Search
Here I argue that it's fundamentally unfair to produce open data and restrict the use of it to an elitist club that knows how to extract meaningful content from it. We, developers that are interested in open data initiatives, should help build the missing corner stone of this technology – search.
Open Street Maps, Wikipedia and WikiData are popular tools amongst a dedicated crowd of mappers and knowledge workers. Open Street Maps is a crowd sourced map of the world, which can be extremely detailed (down to the tree level in some cities). However, some data is usually more present than other, and business data is oftentimes less accurate than on Google, as businesses rarely have a big incentive to add this data: most searches nowadays go through Google anyways. WikiData on the other hand is a free, public structured database of (potentially) all human knowledge, stored as entities that are connected to entity-defining attributes. The entity human, for example, will have an attribute that classifies it as a mammal, and so on. but the real fruits of all the labor has not been harvested as the most useful interface to this data is still missing or incomplete.
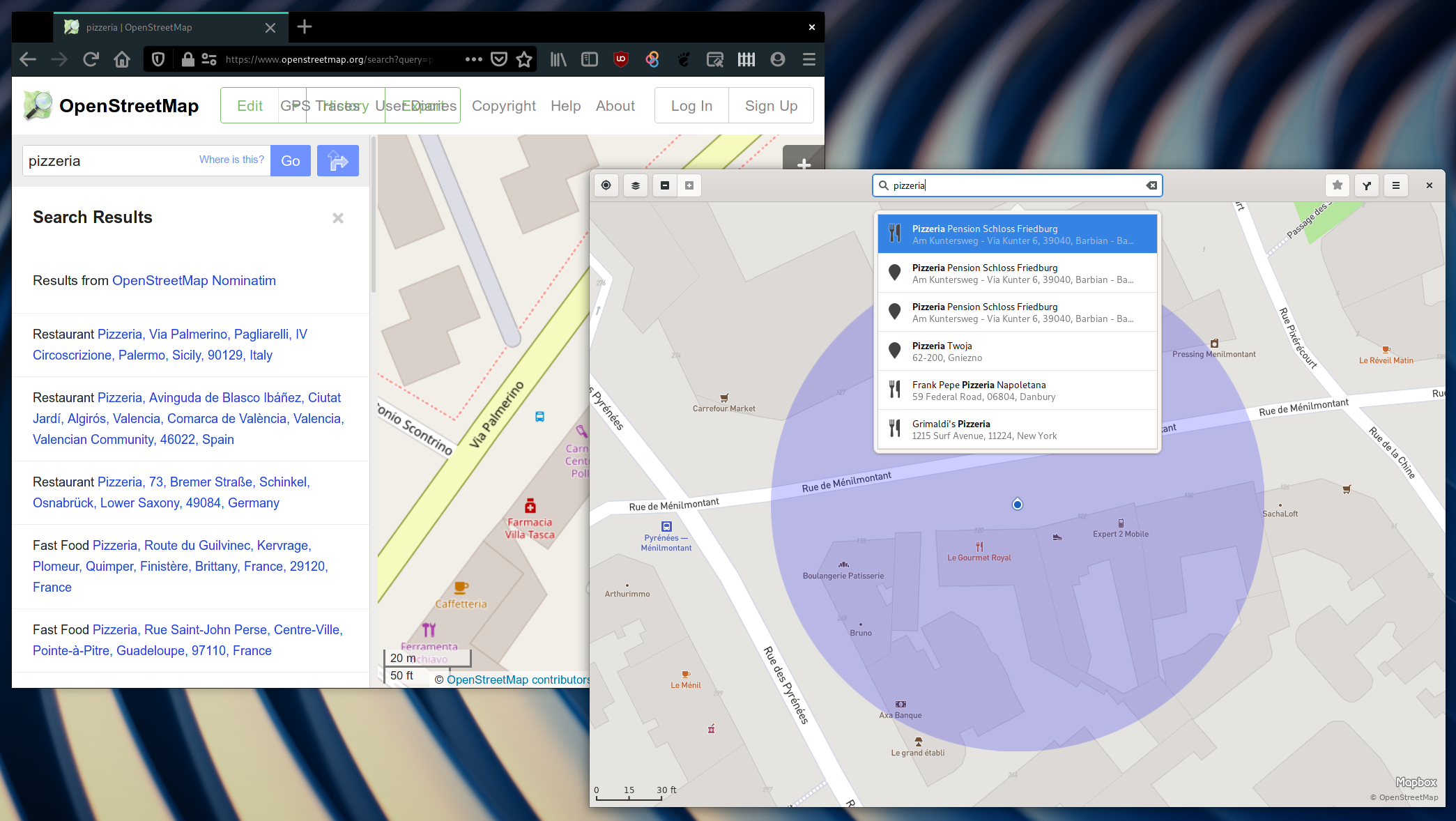
Few things are more frustrating than searching on the Open Street Maps website for something. For example, looking up the search term “pizzeria”: currently it will teleports one to some place in Italy – not at all the expected result when one is living in Paris with plenty of local pizzerias. Good search is a hard problem that concerns mainly two things: understanding what the user is looking for and then retrieving search results sorted in a way that is both transparent and useful.
The motivation of many contributors to help Open Street Maps (OSM) can be summarized by saying that letting Google have a monopoly on Maps is extremely dangerous as it will give them the power to fully shape the way you perceive the world around us. And Google will have the power to guide you wherever their customer pays most for ads. For example, searching for pizzerias at some point in the future could only yield the pizzerias that pay Google a certain extortion fee, and hide all other pizzerias that choose to not take part in this. I genuinely believe this threat is real and we can already observe certain businesses being featured more prominently on Google Maps (did you ever observe those small “Seven Eleven” symbols in Japan?).
A lot of people will argue that matching Google or Bing in terms of capabilities is not easy, and I agree. But I do think that we can get to 80% in a matter of months, and we can figure out further steps afterwards.
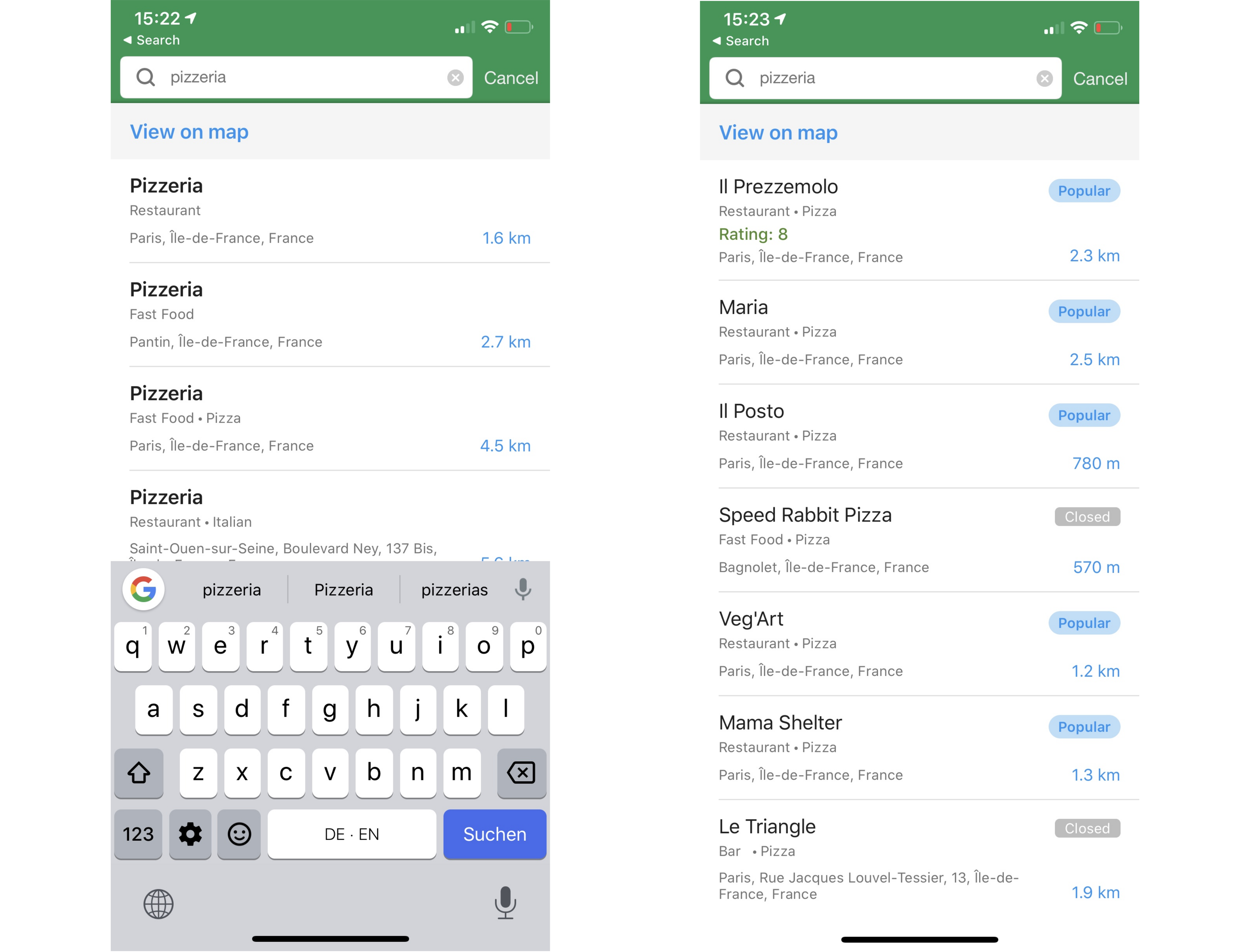
Meaningful search is well within our reach
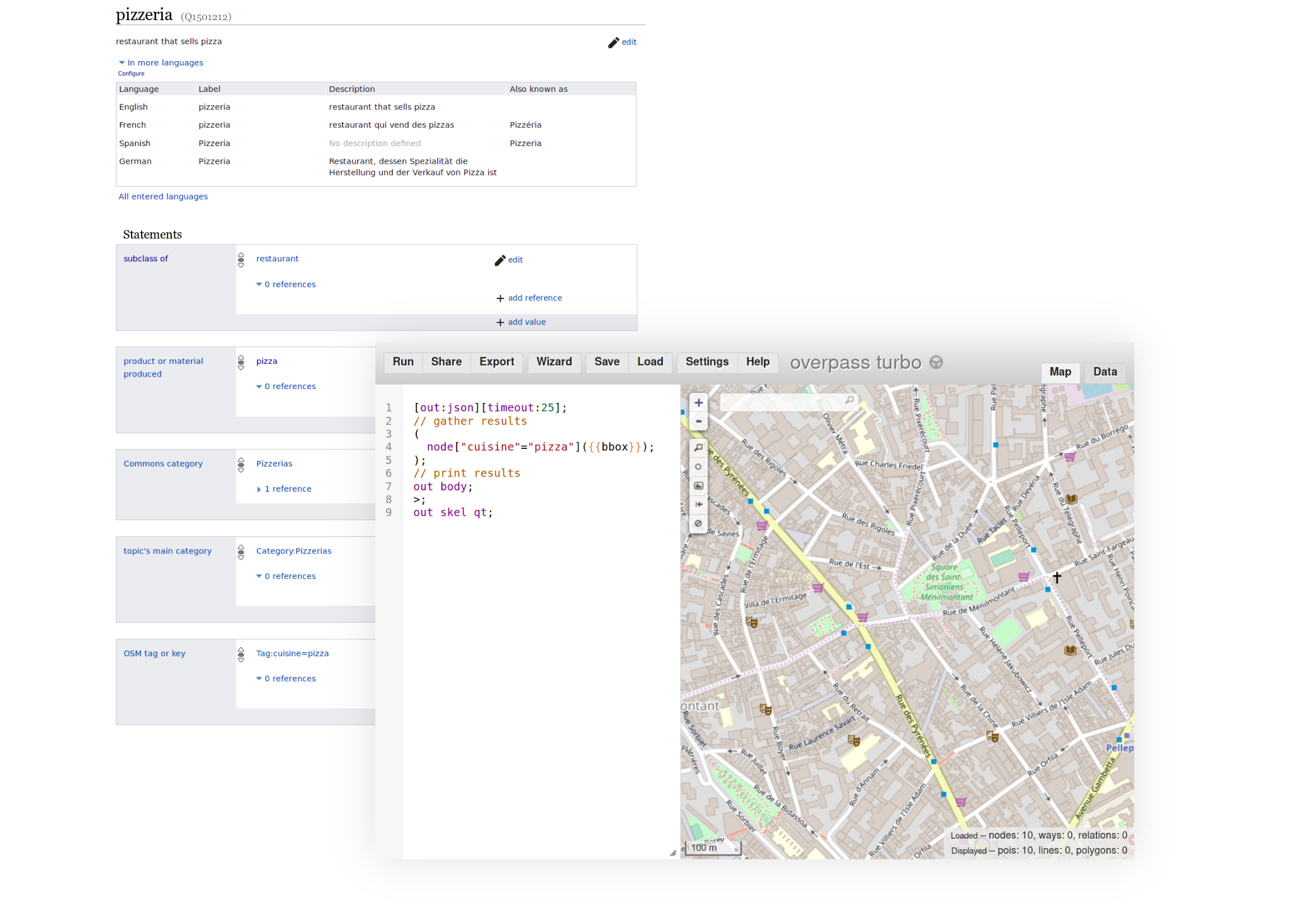
For data that already exists in open, structured databases such as OSM and WikiData, good search is well within our reach. One practical example is the implementation of a multi-language search for pizzerias in the surrounding region. This is currently possible by combining WikiData with OSM. Looking up the pizzeria entity on WikiData will give, amongst other useful statements, the OSM tag as well as the label in many languages (for example пиццерия in Russian, or ピッツェリア in Japanese). We can then feed this data into the OverPass query engine for OSM and extract results near us. The “near us” can be found using the browsers capability of finding a rough geo-localization.
Putting search on the client device
The maps.me software has proven that it is more than feasible to download local maps for offline use, potentially free of continous tracking by software giants. We should have these kind of apps as offline capable websites, as web-browser extensions or as standalone desktop apps.
Sending less queries to Google
Another interesting example is the Siri Knowledge feature by Apple which essentially avoids sending simple queries to Google and rather queries Apples servers for answers. Typing “Volkswagen” will, for example, directly lead you to the official homepage of the Volkswagen AG and similar results. It seems possible that we can implement a similar feature as Open Source that would utilize the knowledge stored in WikiData. This could be installed as a browser extension or it could run as a server hosted by an association funded with donations.
To me, it would be an absolute delight to see the data – that we all helped to collect – be used in this way.
Implementing good open search is our obligation
To summarize, I think it is our obligation to implement a good client side search based on open data because:
- Search brings a necessary empowerement for regular users and frees us of the shackles of technology giants like Google
- Only true search makes our data useful, without it it remains a fun past time for nerds who know how to write SparQL
- Meaningful search will encourage more users to become contributors to data sources such as OSM as it will be a big incentive to improve business coverage
For this we should implement a file format that acts as a database which can be compiled from WikiData and Open Street Maps data. Snapshots of the file should be downloadable (compare with maps.me), and there should be a fuzzy search engine to query this data. The initial version should probably run as a browser extension in Firefox and Chrome.
Future distributed search indices
I believe an interesting future direction for open source search could be to collect multiple disjoint open indices. For example, each website could have an index of things it contains – a newspaper like the NYT could host such an index and make it available for inclusion in search engines or for use in a browser extension. The open source community would have to come up with a reference search index format, as well as with an implementation of an indexer and search engine for this format. The indices could be both, produced by the websites themselves, or collected as part of a collective effort. We should have a website that bundles up these indices into packages of interest (such as all german newspapers etc.) and make it available for update.